Hallucinations of VLMs
Note: That the below is a continous work in progress. This blog’s ethos of writing posts is ellaborated here. All changes can be seen by looking at the history of the markdown file, here.
Motivating Question: Why do VLMs hallucinate? Why do they hallucinate more than LLMs? Can we do anything about it?
Partial Inspiration: paper
Table of Contents
- What are VLMs
- Training Methods
- VLM Hallucinations
- Taxonomy of Hallucinations for VLMs
- Hallucination Detection
- Mitigation Methods
- Citations
- Appendix
What are VLMs?
Vision Language Models (VLMs) or sometimes referred to as LVLMs (Large Vision Language Models) are models that learn using the modalities of images and text. These models work well in zero-shot settings for object localization, image recognition and visual question answering among other things. Examples of VLMs include LLaVA, the DeepSeek VL model, OLMo. There exists a couple of training objectives for VLMs: contrastive, masking, and generative [1]. The most popular method for construcitng these models is to use pre-trained backbones, as it is one of the cheapest and fastest ways to build a VLM. These systems are realized using a projection matrix to create a joint embedding space between the (pre-trained) CLIP encoder and a LLM model. Due to the popularity of such models I will be focusing this article on these types of VLMs.
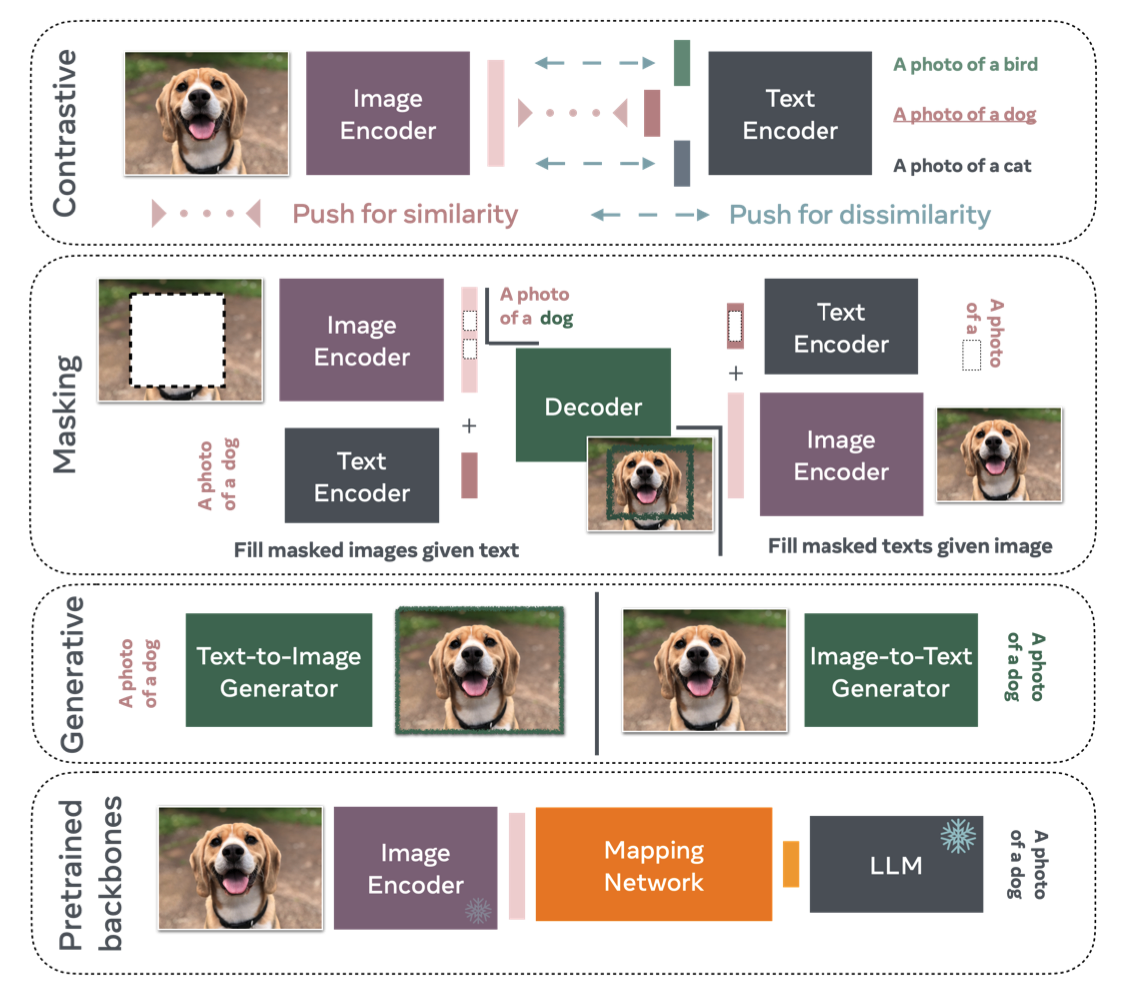
How are they trained?
These can be trained in similar ways to LLMs. Some of the training methods include: Parameter Efficient Finetuning (PEFT), and supervised learning. It should be noted that many of these systems are trained with a contrastive objective. This is due to the nature of the CLIP encoder (which is also trained contrastively). For CLIP, this means that we use image-caption pairs to train the CLIP encoder. Contrastive training would ask the CLIP model to output whether it is a positive sample (the image and caption correspond to each other) or a negative sample (they do not correspond with each other). Along with the fact that the image modality is so rich, the limited nature of the training paradigm makes it difficult for these systems to learn fine-grained details of an image.
VLM Hallucinations?
The struggles with hallucinations for LLMs are well documented in text generation. The same problems occur and appear more grave for VLMs, specifically in the context of long-form visual reasoning. Below we will go through common VLM hallucinations and some of the reasons why they occur.
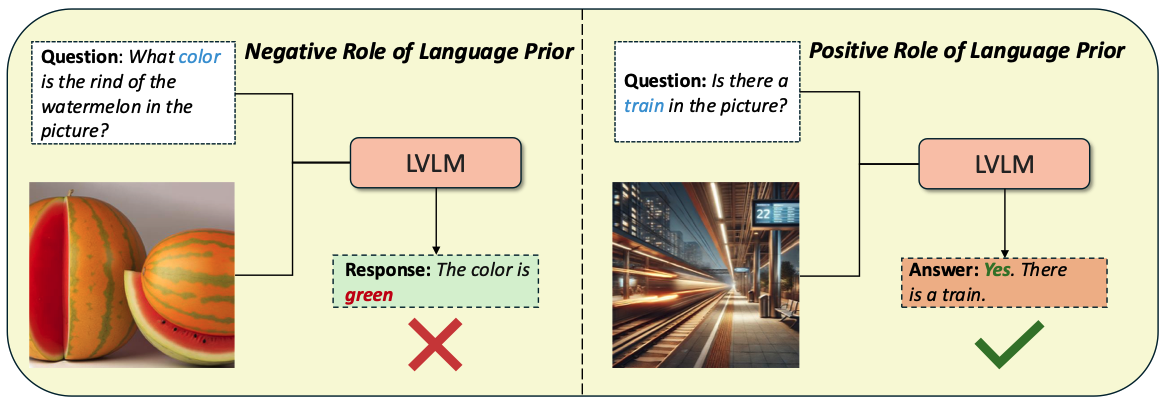
VLM hallucinations differ from normal LLM hallucinations as the latent space for VLMs is more coarse than the latent space for LLMs. This has to do with a carousel of reasons: from the architecture of VLMs, the tendency of VLMs to bias their outputs more on the text modality, the loss function used to align the CLIP and LLM modules, misalignment with abstract human concepts and CLIP’s latent space. In fact, there is reason to believe that the embedding space used by VLMs does not include a rich representation of visual tokens [2].
Are VLMs more hallucination prone that LLMs? Why or why not?
Due to the rich nature of the visual modality and the training objectives of VLMs, these systems are more prone to hallucinations than normal LLMs. This manifests itself in these systems being extremely fragile to changes in answer permutations for Multiple Choice Question Answering (MCQA) and restricts its ability to visually reason [3], [4]. VLMs actually exhibit worse performance in spatial reasoning tasks when visual input is included [5]. The fact of the matter is that this makes VLMs a higher risk than LLM when attacked adversarially.
Taxonomy of VLM hallucinations:
Broadly hallucinations come in two forms: limitations in understanding input images, and the overreliance of lingusitic priors of the LLM. However this manifests itself in various ways:
- Identification and localization of non-existent objects in the input image
- Object, Attribute, relational hallucinations (Same as above basically)
- Action/verb-related Concepts (https://arxiv.org/pdf/2412.14487)
- Misunderstanding of spatial relations between objects in an input image
- Miscounting objects in the image
- Event Hallucination: Describes a non-existent target and constructs completely non-existent events around those imagined targets, including its attributes, relations and actions. (ref: https://arxiv.org/pdf/2402.15721)
-
Modality conflict between the text and image components (arXiv:2403.11116)
- Bias towards Linguistic Priors: specifically in long context or long answers where previous text influences the current output (ref: https://arxiv.org/pdf/2501.15046); or in situations where the input image and a the language model’s world knowledge disagree
- Benign Hallucination: When a linguistic prior is found within the input image, and is used without any regards towards the representations found within the image; a second version of this would be when the model hallucinates without any adverse effects on its final answer in a VQA dataset.
- Image-biased Hallucination: The visual content conflicts with the language model’s world knowledge, and steers the model towards generating false premises, example shown below
- Counterfactual reasoning
(IBD image here)
Hallucination Detection
There are various metrics used to evaulate how hallucination prone models are. These will be discussed in the appendix.
Various benchmarks have been constructed to detect hallucinations. The hope of using these hallucination detection methods is to gather a large enough dataset of negative and positive samples such that these hallucinations can be trained away. However, we remain far from that reality. For one we do not have an agreed upon evaluation metric. Nor, do we have satisfactory evaluation benchmark format to probe the understanding of these models. These evaluation metrics use hallucination metrics that will be discussed in detail in the appendix. Currently, there exists two types of evaluation benchmarks:
- Generative evaluations
- Discriminative evaluations
Generative evaluations apply VLMs to describe the image then evaluate the completions of the VLMs outputs using LLM evaluators. An example of the difference between a discriminative and a generative evaluation framework is shown below. A limitation of this type of evaluation is dependent on the ability of LLMs to remain faithful to the answer, a bar that is rather unstable.
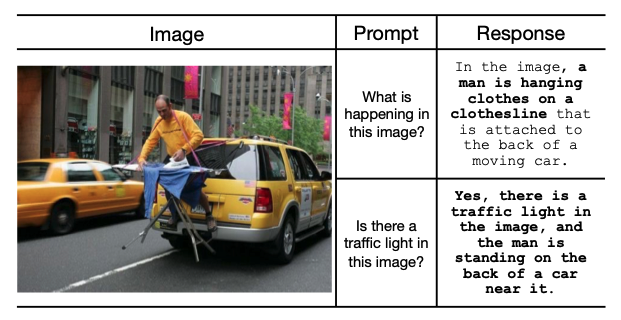
Discriminative evaluations are asked about the existence of objects in an image, in which the VLM must answer in a yes-or-no format. This is very limited and is more an artifiact of the previous benchmarks used before the invention of VLM models (I am speaking pre-2023). However, they still remain a go-to method for hallucination as they are quite cheap to verify and to create.
Both of these types of evaluations are inherently limited in their ability to probe and define hallucinations found within these systems. Recently, there have been efforts in creating evaluations that include generative and discriminative evaluation tasks. AMBER (https://arxiv.org/abs/2311.07397) uses no LLM evaluator, instead using a new metric named AMBER score (which utilizes the CHAIR metric as part of its score). This metric will be further discussed in the appendix. However the format of AMBER benchmark’s task format remains similar to other traditional discriminative and generative benchmarks’ task formats. LongHalQA is a recent effort within the class of benchmarks that contain generative and discriminative tasks. However it differentiates itself two-fold: by including evaluations with and without LLM-evaluators, and by formating tasks as a multi-choice question-answering task. This departure seems to be quite useful as it significantly lowers evaluation times, especially compared to generative evaluations.
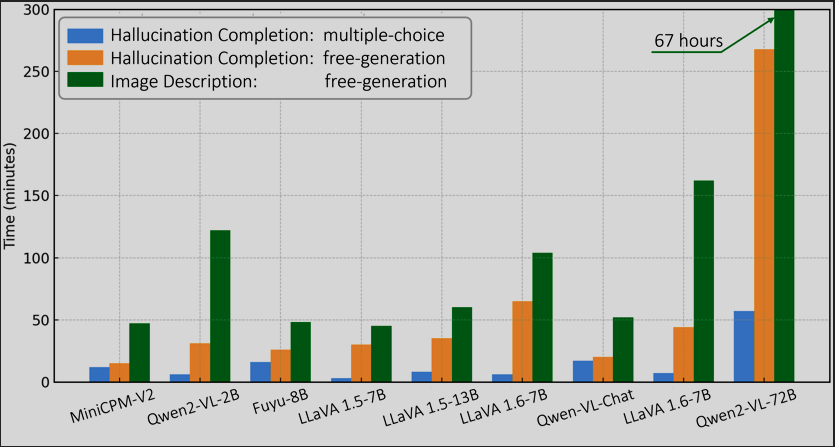
Future evaluations should look more in depth into creating subject-specific benchmarks in a similar vain to LongHalQA. However, there remains much room for exploration specifically in the creation of hallucination tasks that evaluate the reasoning ability of these models or in having a dialogue-level hallucination evaluation benchmark (https://aclanthology.org/2024.findings-emnlp.529.pdf).
Current Hallucination Mitigation methods for VLMs?
There exist numerous proposed solutions to different types of VLM hallucinations:
- Finetuning
- Post training RLHF and DPO
- Contrastive decoding techniques
- Attention Calibration Methods
Below I will include some of these solutions (this will be fleshed out):
Post Training RLHF and DPO
CitationsCitations
[1]
[2]
[3]
[4]
Appendix: Evaluation Benchmarks
POPE: https://github.com/RUCAIBox/POPE
CHAIR: https://arxiv.org/pdf/1809.02156